

Making sure that the team has a holistic view of the event flows throughout an application while still being able to synchronize code, schemas, and documentation is probably harder than actually writing the code.
We can use static site generators like Hugo and Jekyll to write our documentation. We can use Google Docs or embedded docs in any number of "agile" process management tools. Most of the documentation tools available are too general purpose and if we use those we'll probably end up spending all of our time working with boilerplate and not enough time documenting what matters: event flows.
Thankfully there is a beautiful hybrid between a static documentation site generator and the boilerplate we need to document our event sourced applications: Event Catalog. This is an open source project that builds static sites that, in my opinion, render crisp and elegant documentation and visualizations perfect for development teams.
Rather than creating markdown files that contain generic documentation, we instead create markdown files that describe events and services and the message flow between them.
In this screenshot, you can see the list of events contained in the Lunar Frontiers demo application's catalog.
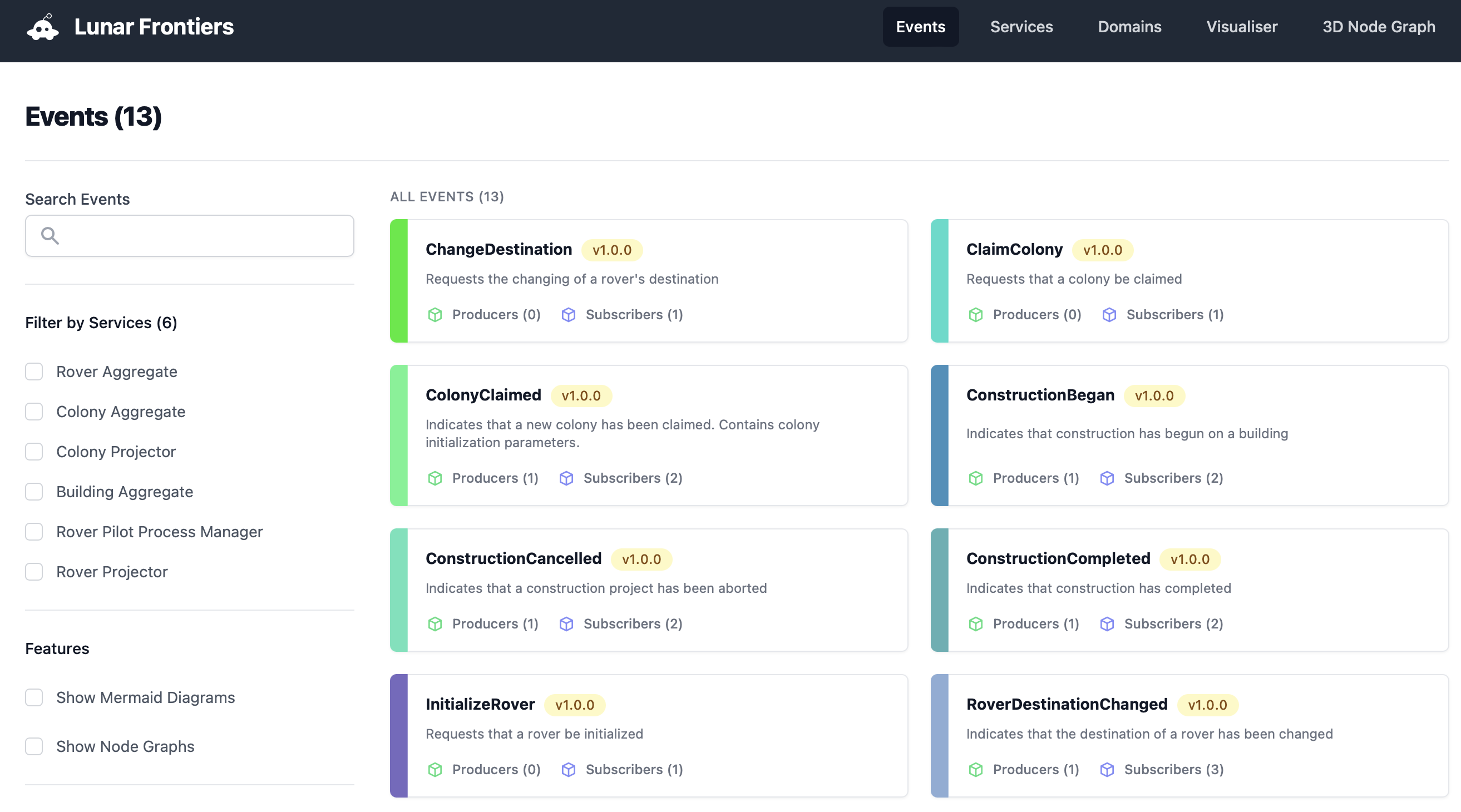
When you click on an individual event, you get a ton of invaluable information. In addition to holding free-form markdown documentation, this page shows you the producers and consumers of the event and we can put a diagram of the flow on page as well.
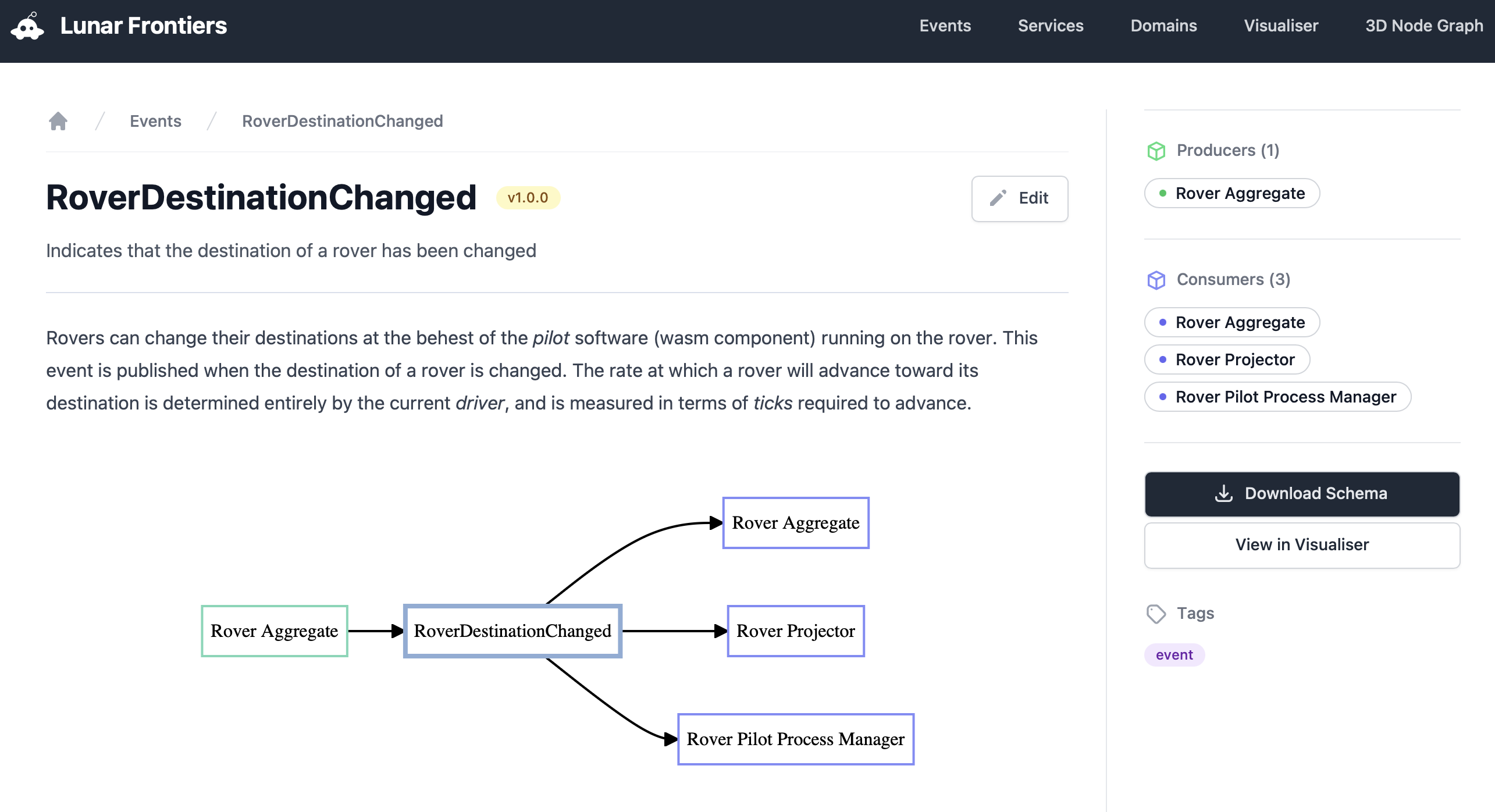
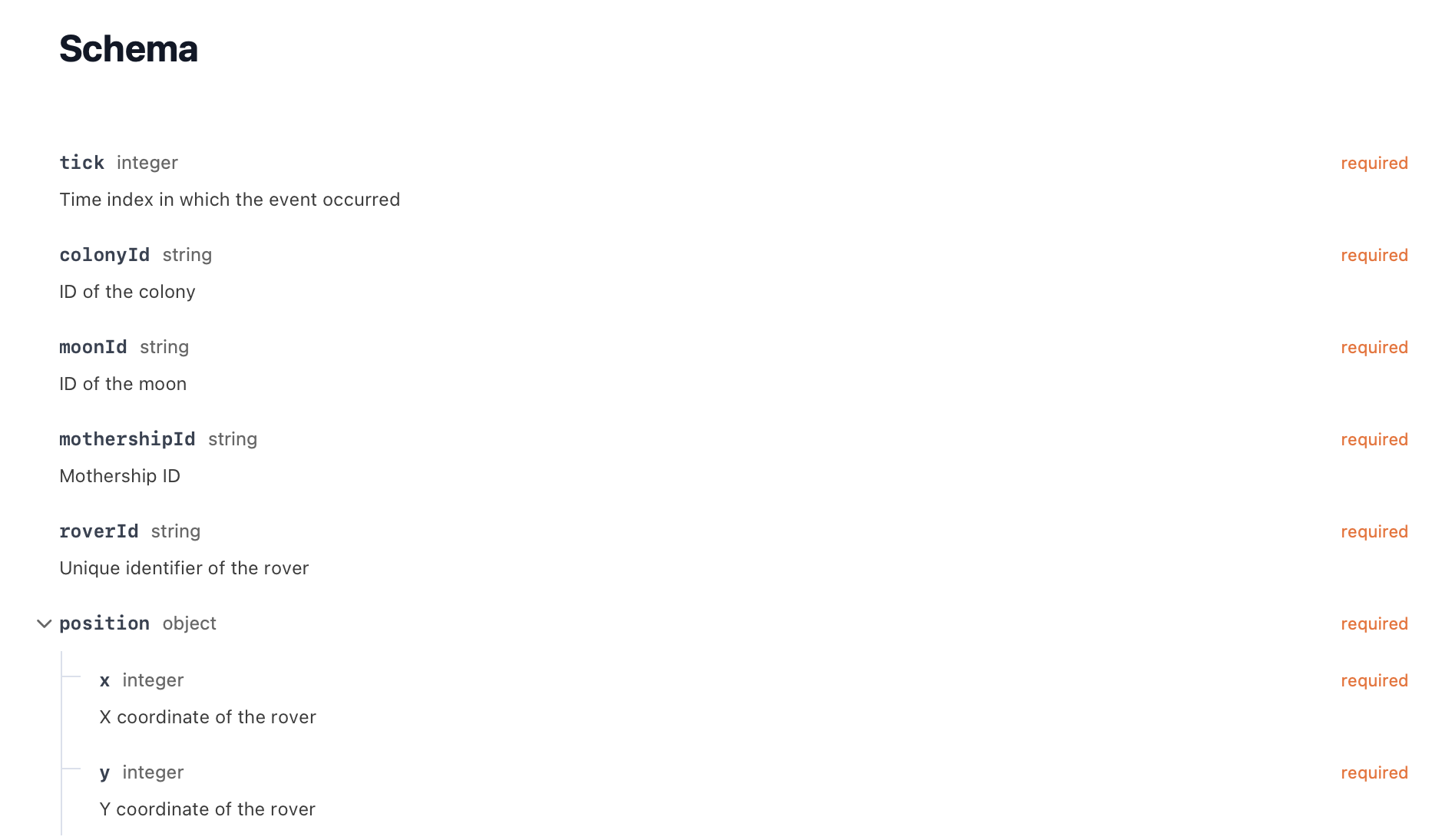
If you scroll down from there, you can actually see a visualization of the JSON schema for this event. Now we have documentation, flow, and schema all in one convenient place.
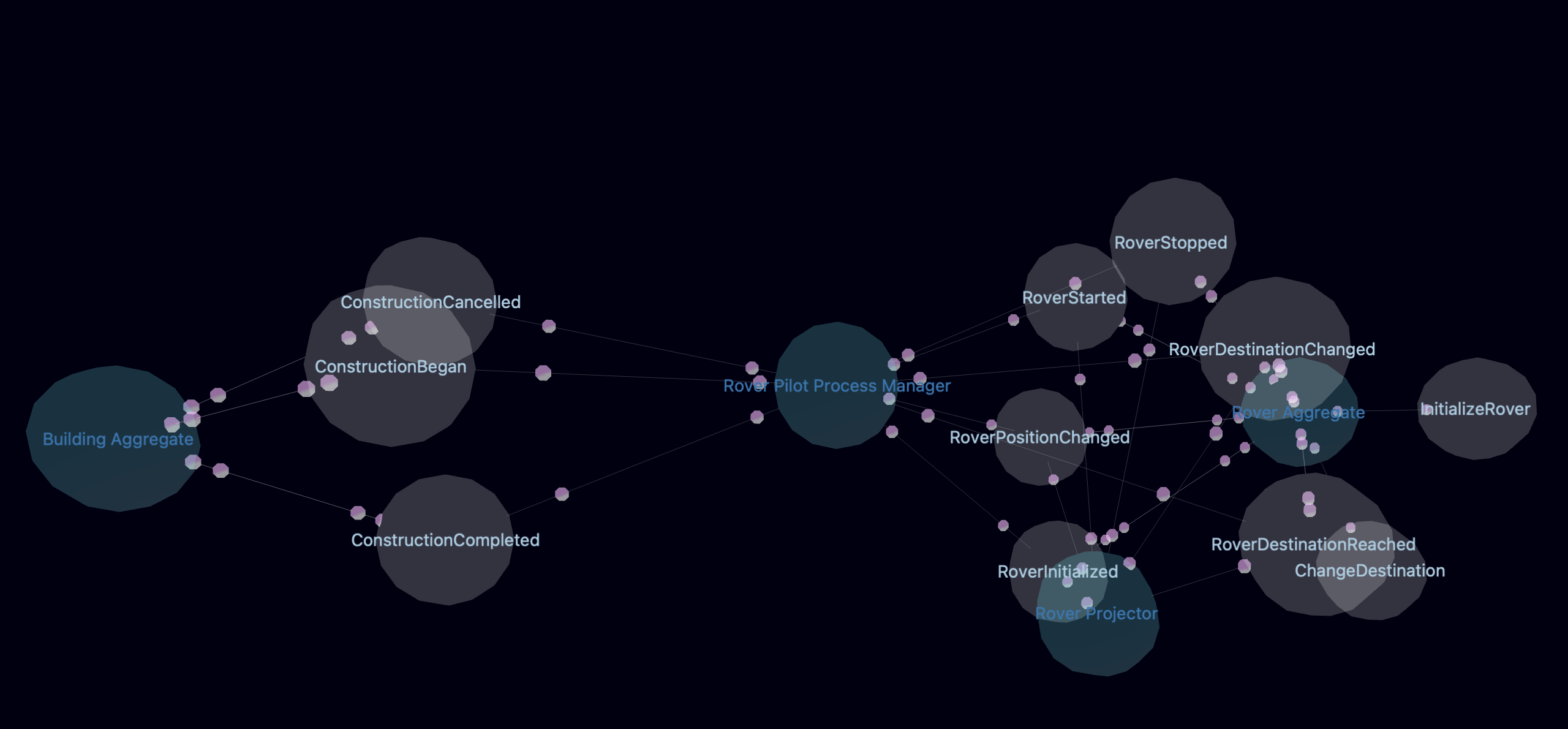
It's amazing enough that we get all of this functionality from Event Catalog, but we actually get more. Earlier I alluded to the need for a holistic view of an event sourced application. In addition to these small graphs that show isolated views, Event Catalog can render multiple different application-wide views, including this one that shows a 3D interactive node graph:
If all a team building an event-sourced application did was add Event Catalog to their roster of tools, I'm convinced they would gain a tremendous boost in productivity. If we add Concordance to this, then we can carry this boost all the way through into our code. That's right, we can generate code from documentation.
Take a look at this markdown file, which is an index.md file for the RoverPositionChanged event:
---
name: RoverPositionChanged
summary: 'Indicates that a rover has moved to a new grid coordinate'
version: 1.0.0
producers:
- 'Rover Aggregate'
consumers:
- 'Rover Projector'
- 'Rover Aggregate'
- 'Rover Pilot Process Manager'
tags:
- label: 'event'
externalLinks: []
badges: []
---
Rover positions change as a result of external stimuli, or _drivers_. When running alongside a simulator-mode driver, the positions will change according to the physics and velocity being managed by the simulator. When running in a "real" environment where live updates are received from an actual rover, the position change is reported as an aggregate of telemetry data.
There might be multiple drivers, including:
- Game driver
- Simulation driver for realistic experimentation
- Real driver, obtaining telemetry from hardware
All drivers operate in the event sourcing role of `injector`.
This event will only be emitted when a _whole_ grid unit has been traversed, and not during partial intervals.
<Mermaid />
## Schema
<SchemaViewer />
There's a lot of really good information here, but take another look at the front matter (the YAML contained between the --- delimiters). From this markdown, we can grab a usable name for the event and we can grab the list of services (event sourcing components) that produce or consume this event. Coupled with the schema.json that sits in the content directory alongside index.md, we have enough metadata to generate data types for the events and commands as well as strongly-typed Rust traits (contracts or interfaces in other languages).
Not only do these traits make it easier for us to write just the code that matters, but we also automatically gain the benefit of being able to break a build upon documentation change. If we add an inbound event to an aggregate in the event catalog, and then go to compile that aggregate in Rust, the build will fail telling us that we haven't handled the new event!
Let's take a look at the next step in documentation-first development: writing a component. In this case, we're going to write code for the Rover Aggregate. First, we can create a new Rust project with cargo new --lib and then set the default target to wasm32-unknown-unknown. There are a couple of Concordance dependencies we need to add to Cargo.toml to gain access to Concordance's procedural macro, but it's otherwise a pretty vanilla project file.
Back in the "old days" (a matter of weeks ago), we used to have to write an aggregate with a single handle_command function and apply_event function. Inside those we'd write manual pattern match expressions to dispatch to code based on the command or event type. Finally, we'd have to deserialize each of the opaque payloads into a strong type (which used to be derived from Smithy files). Even though it could've been much worse, it was an arduous process.
Because we now have all the information we need contained in an Event Catalog site, the Concordance procedural macro can ingest the data from that site and use it to generate all the code that's necessary for the component we're building.
Let's take a look at the first few lines of the Rover Aggregate:
use anyhow::Result;
use serde::{Deserialize, Serialize};
use wasmcloud_interface_logging::error;
mod commands;
mod events;
mod state;
use state::RoverAggregateState;
concordance_gen::generate!({
path: "../eventcatalog",
role: "aggregate",
entity: "rover"
});
Nothing here has come from a Smithy file or even a shared Rust library. There cool stuff happens inside the generate! macro. The path parameter points to the root of an event catalog site (which doesn't need to be running). The role tells the code generator which template to use, and the entity field tells the generator for which entity to generate the code.
Because the entity name is rover and the entity type is an aggregate, we now have a trait generated for us that we can implement to ensure that our code handles everything the documentation says it should: RoverAggregate:
impl RoverAggregate for RoverAggregateImpl {
fn handle_initialize_rover(
&self,
input: InitializeRover,
_state: Option<RoverAggregateState>,
) -> Result<EventList> {
commands::initialize_rover(input)
}
...
}
As a tiny nit, the use of &self here doesn't imply that we should be maintaining state, it's just a current requirement of the code generator. We might be able to get rid of that in the future.
The handle_initialize_rover function takes the command InitializeRover and will in turn return a list of events that correspond to this. There are no side effects here, no mutation, and because we're using wasmCloud security, there's no way this component can attempt to use anything that would produce a side-effect.
Since this command results in an event that will produce a new aggregate, we don't look at the existing state (because it should be None).
Let's take a look at the command handler for initializing a rover:
pub(crate) fn initialize_rover(input: InitializeRover) -> Result<EventList> {
let event = RoverInitialized {
moon_id: input.moon_id,
rover_id: input.rover_id,
mothership_id: input.mothership_id,
tick: input.tick as _,
pilot_key: RoverInitializedPilotKey(input.pilot_key.0),
position: RoverInitializedPosition {
x: input.position.x,
y: input.position.y,
},
};
Ok(vec![Event::new(RoverInitialized::TYPE, STREAM, &event)])
}
For the most part, this event is a standard Rust struct. There is something that may look unusual: the use of the RoverInitializedPilotKey. This convention comes from us using JSON schemas. The PilotKey type is defined in the JSON schema as a separate type because it's actually enforcing a regular expression during validation. That regex is part of the schema I defined in the Event Catalog.
Another advantage of this kind of "localized typing" is that there is very clear barrier between the data types. While we might think it's a good idea to create a new crate and shove all our shared types in there because we've been brainwashed with the DRY principle, having to explicitly convert between "inside" and "outside" data produces cleaner and easier to maintain code and can prevent a whole class of accidental runtime failures in production.
"Later" during the event processing pipeline as managed by Concordance, the aggregate will be delivered this event and the apply_rover_initialized function will be invoked.
fn apply_rover_initialized(
&self,
input: RoverInitialized,
_state: Option<RoverAggregateState>,
) -> Result<StateAck> {
events::apply_rover_initialized(input)
}
So let's take a look at the event handler that will produce a brand new aggregate instance.
pub(crate) fn apply_rover_initialized(input: RoverInitialized) -> Result<StateAck> {
Ok(StateAck::ok(input.into()))
}
Here I've written a converter that takes the RoverInitialized event and turns it into a new rover aggregate state:
mpl From<RoverInitialized> for RoverAggregateState {
fn from(input: RoverInitialized) -> Self {
RoverAggregateState {
rover_id: input.rover_id,
position: (input.position.x as _, input.position.y as _),
moon_id: input.moon_id,
mothership_id: input.mothership_id,
pilot_key: input.pilot_key.0,
destination: None,
current_tick: input.tick as _,
moving: false,
}
}
}
Most of the information is copied over wholesale from the event, but we've decided that the internal rover state can use a tuple of (u32, u32) for the position while the event has an explicit Position struct with x and y members on it.
Obviously we still need to put a tremendous amount of thought into the applications we write. But, if we put some up front time into modeling our application and documenting it in an Event Catalog site, then our code can very nearly be an act of "filling in the blanks". If we know what the flow is supposed to be, and we have a high-level view of the overall system, and we have the schemas of all the data types, we can distill the most error prone part of development (typing code) down to the bare minimum required.
Stay tuned for most posts, videos, and other resources on Concordance development and event sourcing in general! Take some of the examples for a test drive and then let us know what you think in our Discord or Slack or the weekly community meetings. But be gentle, much of this code was literally checked in just a few days ago.